Ok so to simplify you have built a Transformer based Language model which learns from sequences of sentences encoded and applied to a number of attention heads comprised of Query, Key and Value Vectors via their accompanying Weights.
Q vector is the Query, K vector is the Key and V is for Value.
The Value is how significant the word is to the sequence. The Query relates to just THAT word. And the Key relates to how THAT word relates to other words.
Each is computed like this:
Query Vector Q = QWgt x SequenceInputVector
and so on also for K, and V to arrive at the output of this Attention Head:
SequenceOutputVector = Sigmoid(Q*Kt/sqrt(dK)) * V
dK is the dimension of K (My homeworld snigger) Kt is K vector transposed
In the finished Transformer for each layer there should be :
Batches for Training x Number of Attention Heads x Length of the Input Sequence x Length of Output Sequence or Features
NxBatches HxAttentionHeads SxInputSequence DxOutputSequence or DxFeatures
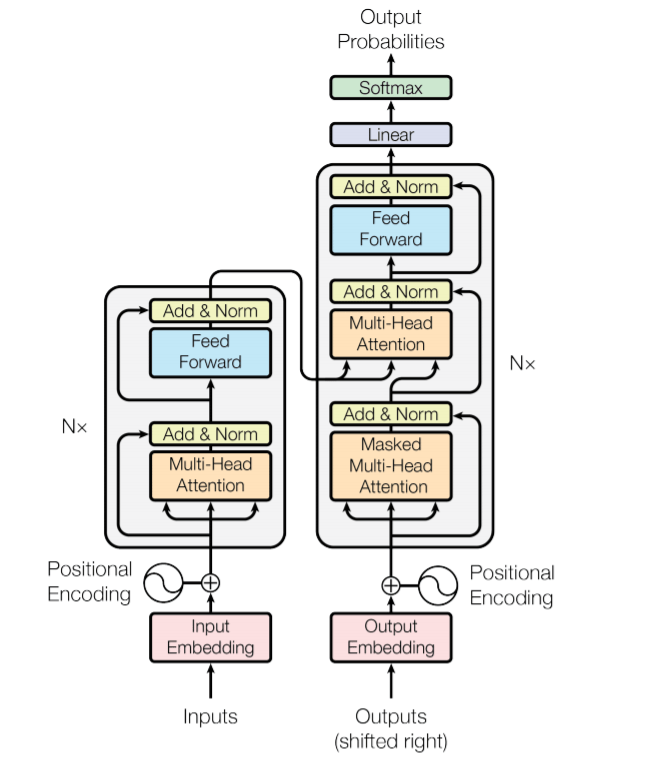
This is the basic formula to creating the output vector from each Head. These attention heads are in the Encoder and Decoder part of the Model. The Encoder gets its inputs from the Input sequence or each proceeding layer.
The decoder gets its input from the Encoder and the final output sequence or proceeding layers.
See image above.
In order to prevent the Decoder from seeing future utterances it is Masked from future words.
Ofcourse there arnt any words just dictionary values as each sequence is tokenized and given positional encoding before hand.
The Mask is what we shall demonstrate here. As it took me a while to figure out but this bit of code illustrates it well:
In this example a mask is built that will be applied to all heads for all batches of data by simply reshaping the mask to the dimensions of the transformer in this case we have an input and output size of 50 with 12 batches and 8 attention heads.
I have simply filled this ficticious Transformer with random values using the TF method for random number generation.
- Code: Select all
import tensorflow as tf;
#Create a Mask using GPT2 method seqlength = 50
i = tf.range(50)[:,None] #2d array
j = tf.range(50) #1d array
m = i >= j -50 + 50 #A 2d Truth table for the mask on this dimension
<tf.Tensor: shape=(50, 50), dtype=bool, numpy=
array([[ True, False, False, ..., False, False, False],
[ True, True, False, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., True, False, False],
[ True, True, True, ..., True, True, False],
[ True, True, True, ..., True, True, True]])>
- Code: Select all
#Create a random number generator
rng = tf.random.Generator.from_seed(1, alg='philox')
#Create a randomly filled tensor with Batch=12 x Heads=8 x SeqInlength=50 x SeqOutlength=50
w = rng.normal([12,8,50,50])
- Code: Select all
m = tf.reshape(m,[1,1,50,50]) #reshape mask to the same shape as the tensor
m = tf.cast(m,float) #convert mask to the same type as the tensor
array([[1., 0., 0., ..., 0., 0., 0.],
[1., 1., 0., ..., 0., 0., 0.],
[1., 1., 1., ..., 0., 0., 0.],
...,
[1., 1., 1., ..., 1., 0., 0.],
[1., 1., 1., ..., 1., 1., 0.],
[1., 1., 1., ..., 1., 1., 1.]], dtype=float32)>
w = w*m - tf.cast(1e10, w.dtype)*(1-m) #apply mask using -inf
#1-m is inverse matrix
<tf.Tensor: shape=(50, 50), dtype=float32, numpy=
array([[0.e+00, 1.e+10, 1.e+10, ..., 1.e+10, 1.e+10, 1.e+10],
[0.e+00, 0.e+00, 1.e+10, ..., 1.e+10, 1.e+10, 1.e+10],
[0.e+00, 0.e+00, 0.e+00, ..., 1.e+10, 1.e+10, 1.e+10],
...,
[0.e+00, 0.e+00, 0.e+00, ..., 0.e+00, 1.e+10, 1.e+10],
[0.e+00, 0.e+00, 0.e+00, ..., 0.e+00, 0.e+00, 1.e+10],
[0.e+00, 0.e+00, 0.e+00, ..., 0.e+00, 0.e+00, 0.e+00]],
dtype=float32)>